Author : Sumantha N T S
Image segmentation is a method in which an image is broken down into various subgroups called Image segments which helps in reducing the complexity of the image to make further processing or analysis of the image simpler. Image segmentation is the practice for classifying the image pixels.
Types of segmentation
-
- Semantic Segmentation : It is a computer vision task of labeling each pixel of the image into a predefined set of classes.
- Instant Segmentation : It is a computer vision task that deals with detecting instances of objects in an image and assigning labels to them.
- Panoptic Segmentation : It is a computer vision task that combines both semantic and instance segmentation.
Let’s discuss the Mask2Former algorithm, which can be used to perform all the types segmentation.
Mask2Former
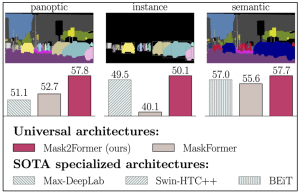
Full form of mask2former is Masked-attention Mask Transformer for Universal Image Segmentation. It’s an universal architecture used for panoptic, instance and semantic segmentation. It’s key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. This model outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
Universal architectures have emerged with DETR(DEtection TRansformer) and show that mask classification architectures with an end-to-end set prediction objective are general enough for any image segmentation task. MaskFormer shows that mask classification based on DETR not only performs well on panoptic segmentation but also achieves state-of-the-art on semantic segmentation. K-Net further extends set prediction to instance segmentation. Unfortunately, these architectures fail to replace specialized models as their performance on particular tasks or datasets is still worse than the best specialized architecture (e.g.,MaskFormer cannot segment instances well which is shown in the image below). Mask2Former is the first architecture that outperforms state-of-the-art specialized architectures on all considered tasks and datasets.
Mask2Former
Mask2Former adopts the same meta architecture as MaskFormer with a backbone, a pixel decoder and a Transformer decoder. We propose a new Transformer decoder with masked attention instead of the standard cross-attention.
- Feature Extractor : SWIN transformer(Shifting Window transformer) is used as backbone feature extractor.
- Pixel decoder : Mask2Former is compatible with any existing pixel decoder module. In MaskFormer, FPN (A Feature Pyramid Network, or FPN, is a feature extractor that takes a single-scale image of an arbitrary size as input, and outputs proportionally sized feature maps at multiple levels, in a fully convolutional fashion.) is chosen as the default for its simplicity. Since goal is to demonstrate strong performance across different segmentation tasks, we use the more advanced multi-scale deformable attention Transformer (MSDeformAttn) as our default pixel decoder. Specifically, we use 6 MSDeformAttn layers applied to feature maps with resolution 1/8, 1/16 and 1/32, and use a simple upsampling layer with lateral connection on the final 1/8 feature map to generate the feature map of resolution 1/4 as the per-pixel embedding. In our ablation study, we show that this pixel decoder provides best results across different segmentation tasks.
- Transformer decoder : Transformer decoder has 3 layers which is repeated *L* times. Use Transformer decoder with masked attention with L = 3 (i.e., 9 layers total) and 100 queries by default. An auxiliary loss is added to every intermediate Transformer decoder layer and to the learnable query features before the Transformer decoder.
- Loss types : Use the binary cross-entropy loss (instead of focal loss) and the dice loss for our mask loss
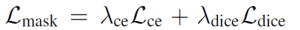
Set Lamdace= 5.0 and Lamdadice = 5.0.
The final loss is a combination of mask loss and classification loss

Set Lamdacls= 2.0 for predictions matched with a ground truth and 0.1 for the “no object,” i.e., predictions that have not been matched with any ground truth.
Why is Masked attention used in Mask2fromer..?
- Transformer-based models have slow convergence due to global context in the cross-attention layer, as it takes many training epochs for cross-attention to learn to attend to localized object regions.
- There is a hypothesis that local features are enough to update query features and context information can be gathered through self-attention.
- For the above mentioned reason mask2former proposes masked attention, a variant of cross-attention that only attends within the foreground region of the predicted mask for each query.
Training Settings
- It uses Detectron2(It is Facebook AI Research’s next generation library that provides state-of-the-art detection and segmentation algorithms.) and follows the updated Mask R-CNN baseline settings for the COCO dataset. More specifically, AdamW optimizer and the step learning rate schedule are used.
- Model uses an initial learning rate of 0.0001 and a weight decay of 0.05 for all backbones. A learning rate multiplier of 0.1 is applied to the backbone and decay the learning rate at 0.9 and 0.95 fractions of the total number of training steps by a factor of 10.
- If not stated otherwise, the model is trained for 50 epochs with a batch size of 16. For data augmentation, the large-scale jittering (LSJ) augmentation is used with a random scale sampled from range 0.1 to 2.0 followed by a fixed size crop to 1024×1024.
- Standard Mask R-CNN inference setting is used where the image is resized with shorter side to 800 and longer side up-to 1333.
- Also model report FLOPs(Floating Point Operation per second) and fps(Frames per second). FLOPs are averaged over 100 validation images (COCO images have varying sizes). Frames-per-second (fps) is measured on a V100 GPU with a batch size of 1 by taking the average runtime on the entire validation set including post-processing time.
Below image shows the performance of Mask2Former over specialized architectures for different tasks.
References:
- Mask2Former Paper
- Mask2Former git-hub repo: https://github.com/facebookresearch/Mask2Former